Welcome to the engineering blog of Wanelo, featuring technical tales of triumph, daring and woe. Sometimes cats. We are definitely hiring. Please email play AT wanelo.com if you're curious!
-
Decoupling Distributed Ruby applications with RabbitMQ
First posted on Wednesday, 03 Feb 2016 by Eric Saxby
A lot of people might be surprised to hear how long it took us to stand up our message bus infrastructure at Wanelo. One of the downsides of focusing on iteration is that fundamental architecture changes can seem extremely intimidating. Embracing iteration means embracing the philosophy that features should be developed with small changes released in small deployments. The idea of spinning up unfamiliar technology, with its necessary Chef code, changing our applications to communicate in a new way, then production-izing the deployment through all the attendant failures and misunderstandings seems… dangerous.
Fortunately “Danger” is our middle name at Wanelo. (Actually, our middle name is “Action.” Wanelo Action Jackson). Having now developed using a messaging infrastructure for almost a year and a half, I would no longer develop applications in any other way.
⟶ Full Post
-
Fully Utilize your Travis Pro Resources by Partitioning your RSpec Build
First posted on Monday, 09 Nov 2015 by James Hart
Split your RSpec build into N equal parts with rspec-parts.
We’ve been subscribed to the Travis Pro service for our CI process for a while. We pay for the Startup plan, which gives us 5 concurrent executors at any given time. Over the last two years, we’ve slowly been pecking away at converting our minitest suite to RSpec. Within the last month, we finally bit the bullet and devoted some developer time to finishing that task. Since we moved from three test suites (minitest, RSpec, and Jasmine) to just two, we had some concurrency available that was not being fully utilized for a single build.
You can see our impressively long 1 hr and 3 minute build below.
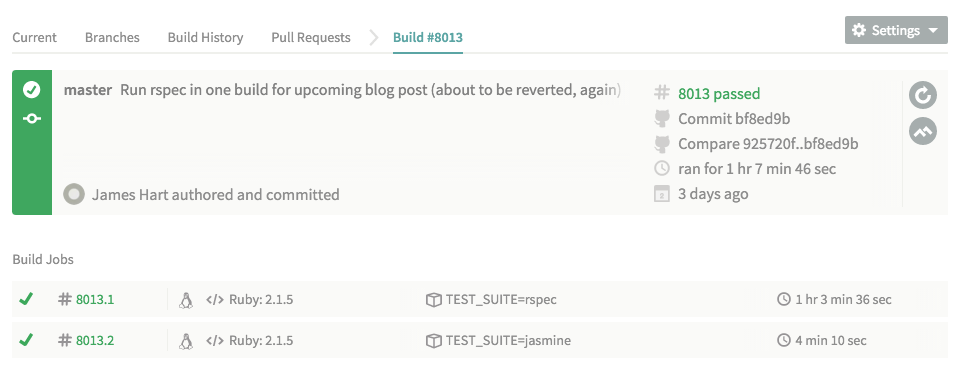
Amazing, right? Our goal then was to take our exceptionally long RSpec build and split it into four evenly split concurrent jobs, thereby using all five executors for one build, allowing us to deploy much quicker.
⟶ Full Post
-
BORAT: Bathroom Occupancy Remote Awareness Technology
First posted on Wednesday, 05 Nov 2014 by Konstantin Gredeskoul
Note: this is the abridged version of a much longer and more detailed technical blog post. If you find youself looking for extra detail, read it from the source.
One of the great things about Wanelo is that we encourage inventiveness of all sorts. Couple that with a bi-weekly hackday, and you get a lot of smart people coming up with a lot of really good ideas.
The project that’s the subject of this blog post does not fit in to the Wanelo roadmap, does not support our production infrastructure and, hell, does not even help with our automated tests. What it does do is make it 100% unambiguous when it is the right time to go the bathroom at our new office.
Shortly after we moved to our current space on Clementina Street in SOMA, the fact that the space has only two single-occupancy bathrooms, each on a separate floor, started to sink in.
I would imagine others had a similar experience as me: a couple times a day, when I really needed to use the restroom, I’d go to the downstairs bathroom only to find its door locked. I’d then run upstairs and find the other one locked as well.. Damn! I’d then come back down only find out that someone else had grabbed the first bathroom while I was upstairs. You can see how this would be a frustrating experience :)
Now multiply that frustration by 35 employees and every work day of the year, and you end up with an actual productivity problem.
Given my foray into Arduino over the last few months, I knew I could come up with a solution. I got approved for a small budget of about $200, and started looking around.

⟶ Full PostThe problem was simple: people needed to know when each bathroom was occupied, or not. We needed something similar to the bathroom occupancy indicator on an airplane. Something everyone could see.
-
Lazy Object Mapping with RestKit
First posted on Friday, 29 Aug 2014 by Server Çimen
In the Wanelo iOS application, we use RestKit to consume RESTful APIs. It’s one of the few libraries that we’ve been able to use without any modifications since the first version of Wanelo. In this post I’ll try to explain how we used Objective-C runtime to lazily map API responses into Obj-C objects using RestKit’s object mapping.

The Problem
While developing our internal API for Wanelo’s native iOS and Android applications, our approach was to provide not only the data the apps need for their current state but also data for possible future states. For example, in the Trending products view, only the product image is needed but the API also includes information about each product (e.g., price, title) which is displayed only if the client navigates to the detail view of the product. The goal is to keep the app feeling fast, and to reduce the number of HTTP calls made which have an overhead, especially on mobile networks.
However this also meant that the application was blocking the user while it was mapping information that wouldn’t be displayed immediately. For large API responses, this caused a significant delay. For example, mapping the Trending products API response on an iPhone 4S was taking longer than 1 second.
Solution
What we needed was a way to map only the immediately needed fields of an object, and map the rest of the fields when they are accessed. Here’s what our Trending products grid and product class looks like:
⟶ Full Post
-
A Story of Counting
First posted on Friday, 20 Jun 2014 by Paul Henry
One of the most important things people do on Wanelo is – save products. Counting how many people saved a given product is therefore an important operation that we have to perform very often.
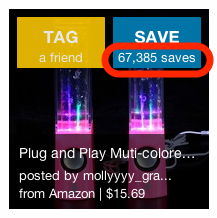
When we first launched our rewrite of Wanelo in Rails, displaying counts was simple. To display the number of saves a user has in the view, we just call
@user.saves.count, right? The counts displayed are accurate and update in real-time on each page refresh. This works for a while but then our traffic grows, we get more data, and more users. Our database starts to slow down and while investigating we notice thousands of slow count queries executing all the time. We know we need to address this or our site will reach a point and crash.Rails Counter Caches
A well known solution to this problem is provided by Rails in the form of counter cache feature in ActiveRecord. You are supposed to add the counter cache column, tell Rails what it is, and the rest is taken care of.
So we drop the configuration into the Save model and deploy with a migration that pre-fills all counter_cache values on users.
class Save < ActiveRecord::Base belongs_to :user, counter_cache: true endAfter this, we changed our views to reference
@user.saves_countand our database load drops dramatically. We’re free to work on features again, woo! But not for long.Our traffic keeps growing and we start to notice occasional deadlocks in our database looking like this:
Deadlock found when trying to get lock; try restarting transaction: UPDATE `users` SET `saves_count` = COALESCE(`saves_count`, 0) + 1 WHERE (`id` = 1067)What now?
⟶ Full Post
-
Code for replication delay
First posted on Wednesday, 11 Jun 2014 by Eric Saxby
After some recent changes to autovacuum settings on our main PostgreSQL databases, we’ve encountered regular significant replication delay on our four streaming replicas. Why this is happening is an interesting subject for another blog post, but it reminded me of some assumptions built into our codebase, as well as some interesting complications of API design.
Tracking Replication
One of the key values of our engineering culture is “knowledge” – we want to know as much as possible about what’s going on with our production infrastructure. Replication delay is no exception: we track it using several tools, such as Nagios, for which we use our custom written nagios plugin for postgresql replication delay (which alerts us when replication falls behind too far), as well as graphing it and displaying this data on a dashboard, using one of our vendor tools Circonus.
Below graph is an example of how we track replication delay across four separate replicas on a logarithmic scale, and overlay it on top of rate of errors coming from the web application and, separately, background jobs. You see two spikes in replication delays, with second spike also correlating with a minor spike in site errors. The two spikes are related to the delay in replication caused by PostgreSQL deliberately pausing replication on one or more replicas, to allow for a particular query to finish running, and is a configurable behavior.
⟶ Full Post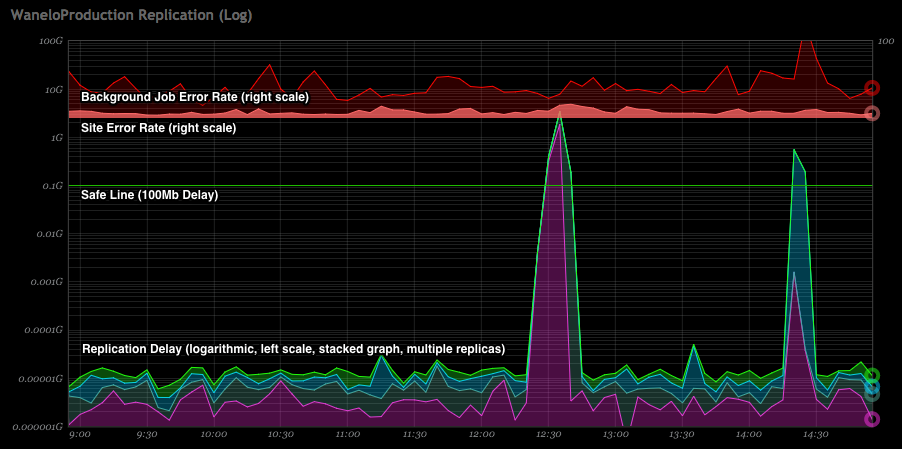
-
Keeping up with Sprout-Wrap
First posted on Tuesday, 27 May 2014 by James Hart
Keeping your sprout-wrap recipes and cookbooks up to date is a good thing to do! It keeps your software secure (because bugs like Heartbleed happen), and it allows your developers to enjoy improving their workstation workflow and processes with the most recent software and tools.
Sprout-wrap has been a moving target lately, and has undergone some recent growing pains. Many cookbooks have moved, and as a result your old recipes and cookbooks will grow stale unless you change your
Cheffileandsoloistrcfile to point to the newest cookbooks and recipes. The good news is, this should be a one time “upgrade.” After pointing towards the newest cookbooks a simplelibrarian-chef updatewill suffice for keeping up to date. This blog post will hold your hand while you perform this one-time upgrade, as I found it to be a bit tricky!Upgrade sprout-osx-base to sprout-base first
If you’re using the
sprout-osx-basecookbook, it has been renamed, and this proves to be tricky when there are dependencies from external cookbooks.Add
sprout-baseto yourCheffile, and keep the oldsprout-osx-basecookbook there for now.cookbook 'sprout-base', :git => 'git://github.com/pivotal-sprout/sprout-base.git' cookbook 'sprout-osx-base', :git => 'git://github.com/pivotal-sprout/sprout-base.git'Adding
sprout-baseandsprout-osx-baseto yourCheffilewill allow for your cookbooks to be backwards compatible. If old cookbooks referencesprout-osx-base, their dependencies will resolve properly. Similarly, when new cookbooks referencesprout-basethey will resolve to those same recipes. We’ll remove thesprout-osx-basecookbook at the end.Try running a
⟶ Full Postlibrarian-chef install. If the cookbooks have been extracted to separate git repositories already you’ll see an error message like this:
-
Romeo is Bleeding
First posted on Thursday, 10 Apr 2014 by Eric Saxby
This week was arguably one of the worst weeks to work in systems operations in the history of the Internet. The revelation of what has been called Heartbleed (CVE-2014-0160), a bug in OpenSSL that allows attackers to read memory from vulnerable servers (and potentially retrieve memory from vulnerable clients) has had many administrators scrambling. This bug makes it trivial for hackers to obtain the private keys to a site’s SSL certificate, as well as private data that might be in-process such as usernames and passwords.
While there is a huge potential for multiple blog posts regarding our learnings from this week, in this post I’ll focus on the current state of affairs, as well as a timeline of events.
tl;dr — wanelo.com was affected by Heartbleed. As of 1am April 8, the public-facing parts of Wanelo were no longer vulnerable. Through the rest of this week we have followed up to ensure that internal components are also secure. This afternoon we deployed new SSL certificates and revoked our old ones. We have no indication that our site was hacked, but there is no way to be certain.
⟶ Full Post
-
Capistrano 3, You've Changed! (Since Version 2)
First posted on Monday, 31 Mar 2014 by James Hart
Capistrano has been around for almost as long as Rails has been around, perhaps short by just a year or so. Back in the early days it introduced much needed sanity into the world of deployment automation, including documenting in code some of the best practices for application deployment, such as the directory layout that included ‘releases’ folder with the ability to roll back, ‘shared’ folder with the ability to maintain continuity from release to release. Capistrano was built upon the concept of having roles for application servers. Finally, being written in Ruby, Capistrano always offered remarkable levels of flexibility and customization. So it should not come as a surprise that it became highly popular, and that subsequent infrastructure automation tools like Chef and Puppet include Capistrano-like deployment automation recipes.
These days it is not uncommon to bump into Python, Java, or Scala applications that are deployed to production using Capistrano (which itself is written in ruby). It’s because a lot of the assumptions that Capistrano makes are not language or framework specific.
It’s worth noting that in it’s entire history of existence, Capistrano have not had an upgrade so dramatically different from the previous version, that in some way it requires rewiring some of your brain neurons to grasp new concepts, new callbacks, and the new mappings between roles and servers, for example.
This blog post represents a typical tale of “We upgraded from version X to version Y. It was hard! But here’s what we learned.”. And amazingly, despite having been released more than 4 months ago, there is still a massive shortage of quality Capistrano 3 documentation (or upgrade paths) online. With this post I am hoping to bridge this gap a tiny bit, and perhaps help a few folks out there upgrading their deployment scripts.
⟶ Full Post
-
12-Step Program for Scaling Web Applications on PostgreSQL
First posted on Friday, 21 Mar 2014 by Konstantin Gredeskoul
On Tuesday night this week Wanelo hosted a monthly meeting of SFPUG
- San Francisco PostgreSQL User Group, and I gave a talk that presented a summary to date of Wanelo’s performance journey to today. The presentation ended upo being much longer than I originally anticipated, and went on for an hour and a half. Whoops! With over a dozen questions near the end, it felt good to share the tips and tricks that we learned while scaling our app.
The presentation got recorded on video, but it’s not a very good quality unfortunately.
In the meantime, you can see the slides for it :)
⟶ Full Post
-
Lake Tahoe is Perfect for fun, skiing, and... hackathons :)
First posted on Monday, 10 Mar 2014
This week entire Wanelo crew packed up and went up to Tahoe City, a small town on the shore of beautiful Lake Tahoe. We’ve done a hackathon before, but never outside of our main office HQ in San Francisco.
On Sunday after dinner everyone pitched their ideas and tried to get a team assembled to work on a project. There have been a total of 19 project submissions, and given that we have 15 engineers, I would call this a huge success.
⟶ Full Post
-
A Brief History of Sprout Wrap
First posted on Monday, 27 Jan 2014
When Wanelo gets a brand new workstation the first thing we install on it is Sprout. Sprout is a collection of OS X-specific recipes that allow you to install common utilities and applications that every Ruby developer has and will appreciate.
⟶ Full Post
-
Just enough client-side error tracking
First posted on Wednesday, 18 Dec 2013
Deploying at Wanelo tends to be high-frequency and low-stress, since we have most aspects of our systems performance graphed in real time. We can roll out new code to a percentage of app servers, monitor app server and db performance, check error rates, and then finish up the deploy.
⟶ Full Post
However, there’s one area where I’ve always wanted better metrics: on the client side. In particular, I want better visibility into uncaught JavaScript exceptions. Client-side error tracking is a notoriously difficult problem -- browser extensions can throw errors, adding noise to your reports; issues may manifest only in certain browsers or with certain network conditions; exception messages tend to be generic, and line-numbers are unhelpful, since scripts are usually minified; data has to be captured and collected from users’ browsers and reported via http before a user navigates to a new page. And on and on.
On the other hand, many sites are moving more and more functionality client-side these days, so it’s becoming increasingly important to know when there are problems in the browser.
-
Multi-process or multi-threaded design for Ruby daemons? GIL to the rescue :)
First posted on Wednesday, 11 Dec 2013
MRI Ruby has a global interpreter lock (GIL), meaning that even when writing multi-threaded Ruby only a single thread is on-CPU at a point in time. Other distributions of Ruby have done away with the GIL, but even in MRI threads can be useful. The Sidekiq background worker gem takes advantage of this, running multiple workers in separate threads within a single process.
⟶ Full Post
If the workload of a job blocks on I/O, Ruby can context-switch to other threads and do other work until the I/O finishes. This could happen when the workload reaches out to an external API, shells out to another command, or is accessing the file system.
If the workload of a process does not block on I/O, it will not benefit from thread switching under a GIL, as it will be, instead, CPU-bound. In this case, multiple processes will be more efficient, and will be able to take better advantage of multi-core systems.
So… why not skip threads and just deal with processes? A number of reasons.
-
Quick heads-up on our upcoming webinar with Joyent on Manta
First posted on Friday, 18 Oct 2013
A few months back, one of our engineers Atasay Gokkaya published a fantastic overview of how we at Wanelo use Joyent's new innovative object store Manta for a massively parallelized user retention analysis, using just a few lines of basic UNIX commands in combination with map/reduce paradigm.
⟶ Full Post
-
Detangling Business Logic in Rails Apps with PORO Events and Observers
First posted on Monday, 05 Aug 2013
With any Rails app that evolves along with substantial user growth and active feature development, pretty soon a moment comes when there appears to be a decent amount of tangled logic, AKA "technical debt."
⟶ Full Post
-
Really Really Really Deleting SMF Service Instances on Illumos
First posted on Tuesday, 23 Jul 2013
We recently ran into a tricky situation with a custom SMF service we maintain on our Joyent SmartOS hosts. The namespace for the service instance (defined in upstream code) had changed, which meant that as our Chef automation upgraded the service instances to the latest code, we ended up with a lot of duplicate service instances that each had a unique namespace.
⟶ Full Post
-
A Cost-effective Approach to Scaling Event-based Data Collection and Analysis
First posted on Friday, 28 Jun 2013
With millions of people now using Wanelo across various platforms, collecting and analyzing user actions and events becomes a pretty fun problem to solve. While in most services user actions generate some aggregated records in database systems and keeping those actions non-aggregated is not explicitly required for the product itself, it is critical for other reasons such as user history, behavioral analytics, spam detection and ad hoc querying.
⟶ Full Post
-
Scaling Wanelo 100x in Six Months
First posted on Saturday, 25 May 2013
We recently gave a talk at the SFRoR Meetup here in San Francisco about how we scaled this rails app to 200K RPM in six months. There were a lot of excellent questions at the meetup, and so we decided to put the slides up on SlideShare.
⟶ Full Post
-
High Read/Write Performance PostgreSQL 9.2 and Joyent Cloud
First posted on Wednesday, 13 Feb 2013
At Wanelo we are pretty ardent fans of PostgreSQL database server, but try not to be dogmatic about it.
I have personally used PostgreSQL since version 7.4, dating back to some time in 2003 or 4. I was always impressed with how easy it was to get PostgreSQL installed on a UNIX system, how quick it was to configure (only two config files to edit), and how simple it was to create and authenticate users.
⟶ Full Post
-
How Alerts Can Tell You When Beyoncé Is On
First posted on Wednesday, 06 Feb 2013

This past weekend a number of us were focused on a really important annual prime time television event (the Puppy Bowl, of course). Turns out other people out there were watching some other sporting event, which leads to the rest of this story.
⟶ Full Post
-
The Case for Vertical Sharding
First posted on Tuesday, 05 Feb 2013
Wanelo's recent surge in popularity rewarded our engineers with a healthy stream of scaling problems to solve.
Among the many performance initiatives launched over the last few weeks, vertical sharding has been the most impactful and interesting so far.
⟶ Full Post
-
The Big Switch How We Rebuilt Wanelo from Scratch and Lived to Tell About It
First posted on Friday, 14 Sep 2012
The Wanelo you see today is a completely different website than the one that existed a few months ago. It’s been rewritten and rebuilt from the ground up, as part of a process that took about two months. We thought we’d share the details of what we did and what we learned, in case someone out there ever finds themselves in a similar situation, weighing the risks of either working with a legacy stack or going full steam ahead with a rewrite.
⟶ Full Post