After some recent changes to autovacuum settings on our main PostgreSQL databases, we’ve encountered regular significant replication delay on our four streaming replicas. Why this is happening is an interesting subject for another blog post, but it reminded me of some assumptions built into our codebase, as well as some interesting complications of API design.
Tracking Replication
One of the key values of our engineering culture is “knowledge” – we want to know as much as possible about what’s going on with our production infrastructure. Replication delay is no exception: we track it using several tools, such as Nagios, for which we use our custom written nagios plugin for postgresql replication delay (which alerts us when replication falls behind too far), as well as graphing it and displaying this data on a dashboard, using one of our vendor tools Circonus.
Below graph is an example of how we track replication delay across four separate replicas on a logarithmic scale, and overlay it on top of rate of errors coming from the web application and, separately, background jobs. You see two spikes in replication delays, with second spike also correlating with a minor spike in site errors. The two spikes are related to the delay in replication caused by PostgreSQL deliberately pausing replication on one or more replicas, to allow for a particular query to finish running, and is a configurable behavior.
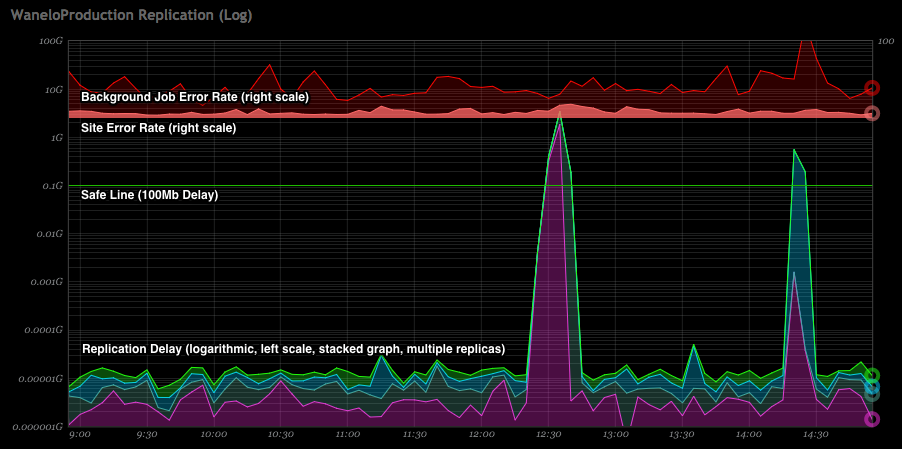
We use the open source database adapter Makara in order to manage read/write splitting of SQL queries from Rails. This has worked well for us, but occasionally we get spikes of errors from the website as well as from various Sidekiq workers. If a user creates a new collection, for instance, various Sidekiq jobs need to do work on or using that new collection. During any significant replication lag (even of a minute’s worth of data), these jobs would fail with ActiveRecord::NotFound errors. Some pages or API endpoints return 404 or 500 errors, depending on how well various code responds to the missing records. When this first occurred, it caused much hand-wringing among the engineering department and many bug reports from others on the team. Why would a record sometimes be there, and sometimes not?
Replication delay
When a master database is overloaded with queries, it can fall behind on streaming new transaction logs to replicas. When a replica is overloaded writing to disk or handling query load, it can fall behind on applying transaction logs to its in-memory data store. When this happens, a record that exists on the master may not be present or may not be viewable on one or more streaming replicas.
Sidekiq is a tool for writing background workers that consume messages and do work outside of a normal web request/response cycle. When queues are healthy (i.e. not overloaded), though, Sidekiq may consume a job faster than replication has a chance to catch up on read-only replicas. When this happens, errors are bound to occur.
Delaying delayed jobs
When using read/write splitting of SQL queries, a bit of fudging should always be expected. It’s normal to expect a few seconds of delay at all times. We’ve found that adding a bit of queue delay to all workers can help with this solution. In Sidekiq terms, this can be implemented with the following change:
MyWorker.perform_async(*stuffs)
|
V
MyWorker.perform_in(10.seconds, *stuffs)
There’s only so far that this will take you, however.
Assume replication delay
One of the reasons we appreciate Makara is that it is easy to understand and easy to extend. It also has features such as sticky master built-in. For example, if for any reason a query must be directed at a master database (a write query, for instance), any further requests in that request cycle will go to the master.
In our deployed version of Makara, this is done with some global state that is reset at the end of the response via Rack middleware. We make sure that all of our Sidekiq workers unstick master connections using our own custom base class, but this could also be done with a simple server middleware class.
Assuming that at some point replication delay will cause a situation where a record or records exist on the master but not on a read replica, we can write a simple method that handles these situations:
DatabaseHelper.failover_on(:blank?) do
Collection.where(user_id: current_user.id).all
end
The implementation of this will be specific to your database adapter, but it needs a few simple steps:
- Call the block
- Send the test method to the return value of the block
- If the test method returns true, stick the database adapter to master and re-call the block
Where can this go wrong?
- If the block returns an ActiveRecord::Relation that has not actually executed, your test method may generate count queries. If you put this into a high-load endpoint, thousands of extra count queries could cause new problems.
- If the block executes SQL, you are not deferring your queries. If you are expecting deferred queries to skip execution due to view caching, you may be surprised.
- Are there any caching layers in your adapter that could skip re-executing the query?
- What if
:empty?or:blank?are valid responses? Can you even test for replication delay?
Sidekiq has a built-in retry queue, so in some cases it may be easier to just let the initial job fail and be retried enough times to ensure that eventually it will succeed when replication catches up. Extraneous errors generate a lot of noise, however, and can train an engineering department to ignore warnings when real problems occur.
API design decisions?
If an API endpoint relies on some persisted state, it’s possible that state changes will not be immediately reflected to consumers when your databases suffer from replication lag. For instance, an endpoint may return different information based on the settings saved for the current user. What happens when a user updates their settings but the endpoint returns data based on their old configuration?
In some cases, it might be preferred for the endpoint not to rely on saved state. It may be preferred for clients to retain a local copy of the settings, which can be used to query the API differently. There are positives and negatives to this approach.
Replication delay is not the end of the world
Significant replication delay in databases causes a host of problems. In the long term, it can be an indicator of many issues; resource saturation on the database servers or networks, load thresholds, improperly tuned servers (block size mismatches, vacuum settings, etc) and other factors can all create or exacerbate replication problems. If ignored, these replication problems can become bad enough that replication fails entirely. Replication delay is an important metric to monitor and generate alerts on, so that when it becomes problematic people can be tasked to investigate and solve the core problems.
There is no way to guarantee that small delays do not happen, however.
— Eric