Deploying at Wanelo tends to be high-frequency and low-stress, since we have most aspects of our systems performance graphed in real time. We can roll out new code to a percentage of app servers, monitor app server and db performance, check error rates, and then finish up the deploy.
However, there’s one area where I’ve always wanted better metrics: on the client side. In particular, I want better visibility into uncaught JavaScript exceptions. Client-side error tracking is a notoriously difficult problem -- browser extensions can throw errors, adding noise to your reports; issues may manifest only in certain browsers or with certain network conditions; exception messages tend to be generic, and line-numbers are unhelpful, since scripts are usually minified; data has to be captured and collected from users’ browsers and reported via http before a user navigates to a new page. And on and on.
On the other hand, many sites are moving more and more functionality client-side these days, so it’s becoming increasingly important to know when there are problems in the browser.
I have yet to see a great solution to this problem, so I try to ask about other companies’ client-side error tracking whenever I can. I usually hear one of two answers: A.) We don’t track them (but we’d like to), or B.) We built our own in-house tracking system; sometimes it helps us catch issues, but usually it’s a firehose of random errors that we can’t trace back to a particular issue.
There’s a middle path between these two answers that I think will end up being the “just right” solution for us: client-side error rate tracking. Essentially, ignore all error messages and calculate the total count of client side errors per minute relative to “page views." The goal of this sort of tracking isn’t to pinpoint each new client-side issue, but just to answer the question: did we break something during this deploy that’s going to prevent our users from having a good experience on the site?
We wanted to deploy a quick solution without a lot of work, to see if it would be a fit; we didn’t want to embark on a client-side metrics yak shave. We also came up with a few other nice-to-haves:
- tracking should not require any new services or infrastructure, or add much load to our current infrastructure
- data needs to be graphable alongside our backend metrics
- data needs to be available fast, ideally in around 5 minutes or less
Most of our backend metrics are graphed in Circonus, and we display the most relevant ones on a big dashboard in the office. The graphs and meters on the dashboard are calibrated well enough that they go red infrequently, and when they do, we notice (and usually take action). My aspiration for our client-side error tracking is for it to be on this dashboard and work the same way — updating in real-time and going red if (and only if) there’s an actionable issue. Luckily, Circonus can consume data from a lot of different sources, including metrics from hosted third-party tools like New Relic — in fact, it can do custom checks to any JSON endpoint that is public, or that allows authentication with a URL param or request header.
The custom-check capability is a win, because it lets us use Fastly (our CDN) to serve our client-side error beacon and then set up a Circonus check to the Fastly stats API to get a count of errors. Fastly isn't exactly intended for this use case, so it requires a bit of configuring to set up, but there are a few advantages: first, a spike in error beacon traffic won’t increase load on any of our infrastructure; second, we make extensive use of Fastly for serving assets and pages, so we already have a reason to track Fastly day to day (and, of course, error pixels load fast : )
Setup
1. Add an on-error handler that loads the error beacon
The first step was to add an on-error handler near the top of our main application JavaScript file. We kept it simple. If you already have on-error handlers (or your third-party scripts use them) you may want to have the handler call the previous handler when it's done. Otherwise, the on-error function just needs to insert an img tag into the page when an error is caught.
2. Deploy the beacon to Fastly
Second, we deployed our error pixel on Fastly. For Fastly, we set the pixel up on its own domain so it would be easy to track all of our client-side error traffic as a separate service. We also had to update the default VCL slightly — we wanted the backend TTL to be long, so Fastly never needs to fetch a new version of the asset from our servers, but set the response cache control headers on the asset to be short (max-age=1), so new errors will always trigger a request to Fastly (i.e., the asset shouldn’t be loaded from the browser cache).
3. Set up a Circonus JSON check to the Fastly API
Third, we set up a Circonus JSON check to poll the Fastly stats API every minute. Since Fastly has some rate limits on pulling very recent data from the stats API, we have the check get a count of error pixel requests from 30 minutes ago. This gets us a count of errors per minute — to turn it into a rate (i.e., percentage of page views that have a JavaScript error), we graph the ratio of errors per that minute to pageviews per that minute. (We’re using stats on our CSS and JS asset requests to calculate number of pageviews, assuming some number of asset requests per minute, but if you wanted to be more precise, you could add a “pageviews” tracking beacon to your web layouts and use that rate for your denominator.)
If we want to see this data immediately, without the 30-minute delay, we can -- we just need to log into Fastly and look at the real-time graphs on the Fastly dashboard.
And that's it!
Results
We’re successfully collecting this data now, and we’re graphing it in Circonus. This is the "errors last week" view:
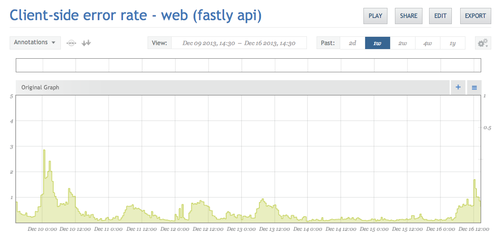
So far, this experiment looks like a qualified success. We were able to roll out tracking with less than a day of work, and, if something major gets broken, we’ll see a spike in the graph in 30 minutes. However, since this metric is a bit noisier than others we collect, it takes a fairly widespread issue before it’s obvious on the graph. So, there are some ways we want to improve this tracking in the future...
TODO:
1. Segmented rates by browser
The top priority for future work here is adding error rates by browser/operating system (and possibly browser version). Right now our graphs will tell us if there’s an issue on a popular page in all (or most) browsers, but if we had an issue in just one browser, like Internet Explorer 9, it might get lost in the noise. It would be great to have a composite graph that’s composed of stacked rates for each major browser, so we could see if one was growing out of the proportion to the others.
2. Closer-to-real-time data
The data we pull from the Fastly API is a bit older than the data in most of our Circonus graphs, so there’s some mental overhead to remembering to offset the one graph from the others by 30 minutes to think about overall systems health. It would be great to be able to pull fresher data from the Fastly API without the rate limits, or be able to offset the graphs in Circonus by a set amount of time.
Addendum
Other collection options: Google Analytics
If your tools don’t allow you to beacon data some place and graph it, but you still want this sort of tracking, you may be able to do similar tracking with your web analytics solution. For example, instead of an image beacon, you could send a Google Analytics custom variable. On the plus side, a lot of web analytics tools track browser and OS version information by default; however, if this tracking relies on JavaScript, it may not run in some cases, depending on where the original uncaught exception happened.
On the other hand, a site as large as Wanelo no longer qualifies for full data collection on the free Google Analytics service, so we use 5% sampling. Clearly, sampling client-side errors is not the best idea :)
Where this won’t work
For us, I think graphing a client-side error rate is the happy medium between having no visibility into client-side exceptions and having a high-maintenance error-tracking service. However, there are use cases where this technique wouldn’t be a great fit: for example, if your company does large, infrequent releases, error rates may not be enough information. Our releases tend to be relatively small, so usually, if we see error rates climbing, we know which code changes are the likely culprits, and where to start looking for the issue.
- Emily