One of the most important things people do on Wanelo is – save products. Counting how many people saved a given product is therefore an important operation that we have to perform very often.
When we first launched our rewrite of Wanelo in Rails,
displaying counts was simple. To display the number of saves a user has in the view,
we just call @user.saves.count, right? The counts displayed are accurate and
update in real-time on each page refresh. This works for a while but then our traffic
grows, we get more data, and more users. Our database starts to slow down and while
investigating we notice thousands of slow count queries executing all the time. We
know we need to address this or our site will reach a point and crash.
Rails Counter Caches
A well known solution to this problem is provided by Rails in the form of counter cache feature in ActiveRecord. You are supposed to add the counter cache column, tell Rails what it is, and the rest is taken care of.
So we drop the configuration into the Save model and deploy with a migration that pre-fills all counter_cache values on users.
class Save < ActiveRecord::Base
belongs_to :user, counter_cache: true
end
After this, we changed our views to reference @user.saves_count and our database load
drops dramatically. We’re free to work on features again, woo! But not for long.
Our traffic keeps growing and we start to notice occasional deadlocks in our database looking like this:
Deadlock found when trying to get lock; try restarting transaction:
UPDATE `users` SET `saves_count` = COALESCE(`saves_count`, 0) + 1 WHERE (`id` = 1067)
What now?
Back to Full Counts, but Buffered
We’re now in a situation when the same rows are being updated at the same time or close to the same time. We need to solve the locking or else the number of errors being thrown by update or delete endpoints will grow exponentially. We take a step back and review the major components in our technology stack.
- Postgres (Primary Database, see how we scaled it)
- Unicorn (Serving real-time user HTTP requests)
- Sidekiq (Performing long running or delayed jobs that don’t block user requests)
- Sidekiq Unique Jobs (Uniques sidekiq jobs so that the jobs are de-duped based on their parameters)
- Nginx/Haproxy (Handling routing/loading balancing)
Sidekiq has the ability to schedule jobs to be run at a certain point in the future. We decide to create a job to be enqueued after a user saves a product that’s delayed by 2 minutes.
class UserSavesCountWorker
sidekiq_options unique: true
# Job is uniqued on user_id
def perform(user_id)
user = User.find(user_id)
# this performs an actual 'SELECT COUNT(*)...' but only once per job
user.update_attribute(:saves_count, user.saves.count)
end
end
class Save
after_create :enqueue_saves_count_worker
def enqueue_saves_count_worker
UserSavesCountWorker.perform_in(2.minutes, self.user_id)
end
end
The UserSavesCountWorker ensures that even if a user saves 5 products in a 2 minute period,
we only run the count query once. This takes a significant load off our database especially when
this is applied to all counters everywhere. This process buys us another month until traffic reaches
another threshold and we’re STILL runnning too many counts. Time to take a step back to the whiteboard!
Updating Counts in Redis
We realize that we need to take a look at another datastore to hold these counts, even if for a
temporary amount of time. Redis has two operations that fit the requirement of counting perfectly;
INCR and DECR. These
can be leveraged to buffer counts into Redis before saving them to the database, bypassing asking
the database for counts.
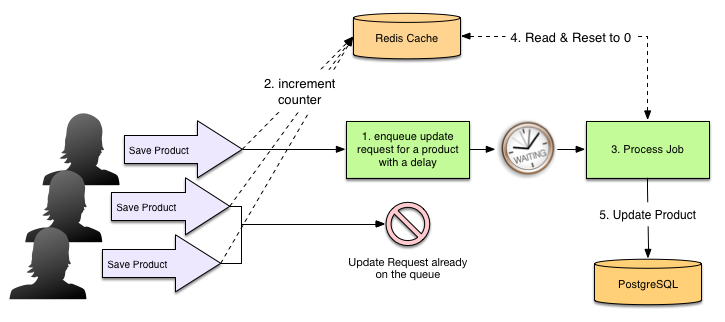
The above diagram outlines the resulting flow of the data as multiple concurrent users are saving products, possibly the same product, and how we are avoiding updating the same product many times in a row. We start with a zero value in Redis, and increment it as new products are saved, until a background job flushes it by updating the database value to the sum of previous value, and the one in Redis, and then resetting Redis value back to zero. Rinse repeat.
After we deployed this system, database load caused by counts completely disappeared because we simply weren’t running any. The story is mostly perfect at this point except for the part where Redis goes away temporarily for any number of reasons (the cloud is not actually always there no matter how much you want it to be, turns out). To solve this issue, we introduced recalculations that run every 3 - 6 hours depending on what’s being recalculated. These recalculations run full count queries to ensure values are completely up to date. We disabled recalculations on very popular objects such as Products as the query is simply to expensive.
All of this work is open-source and can be dropped into an existing Rails app. The buffer datastore and background jobs backend can be customized, but we recommend Sidekiq for background jobs, and Redis as the buffer datastore. We use the same gem in production.
Get the gem here: https://github.com/wanelo/counter-cache
Work is on-going and we’ll be making constant updates to the gem, as things change in our infrastructure. Please feel free to send pull-requests and report issues!
Future Improvements
One of the possible future features could be providing read-time consistency by returning the sum of the buffered value and the database value, whenever the value needs to be displayed. Right now accessing the counter cache column shows the database value, which may be slightly out of date. We haven’t bumped into a need to show truly real time counters yet, but when we do, we’ll be sure to add this feature.
– Paul